MSc. Dissertations from Previous Years
A Supervised Approach to Extractive Summarisation of Scientific Papers
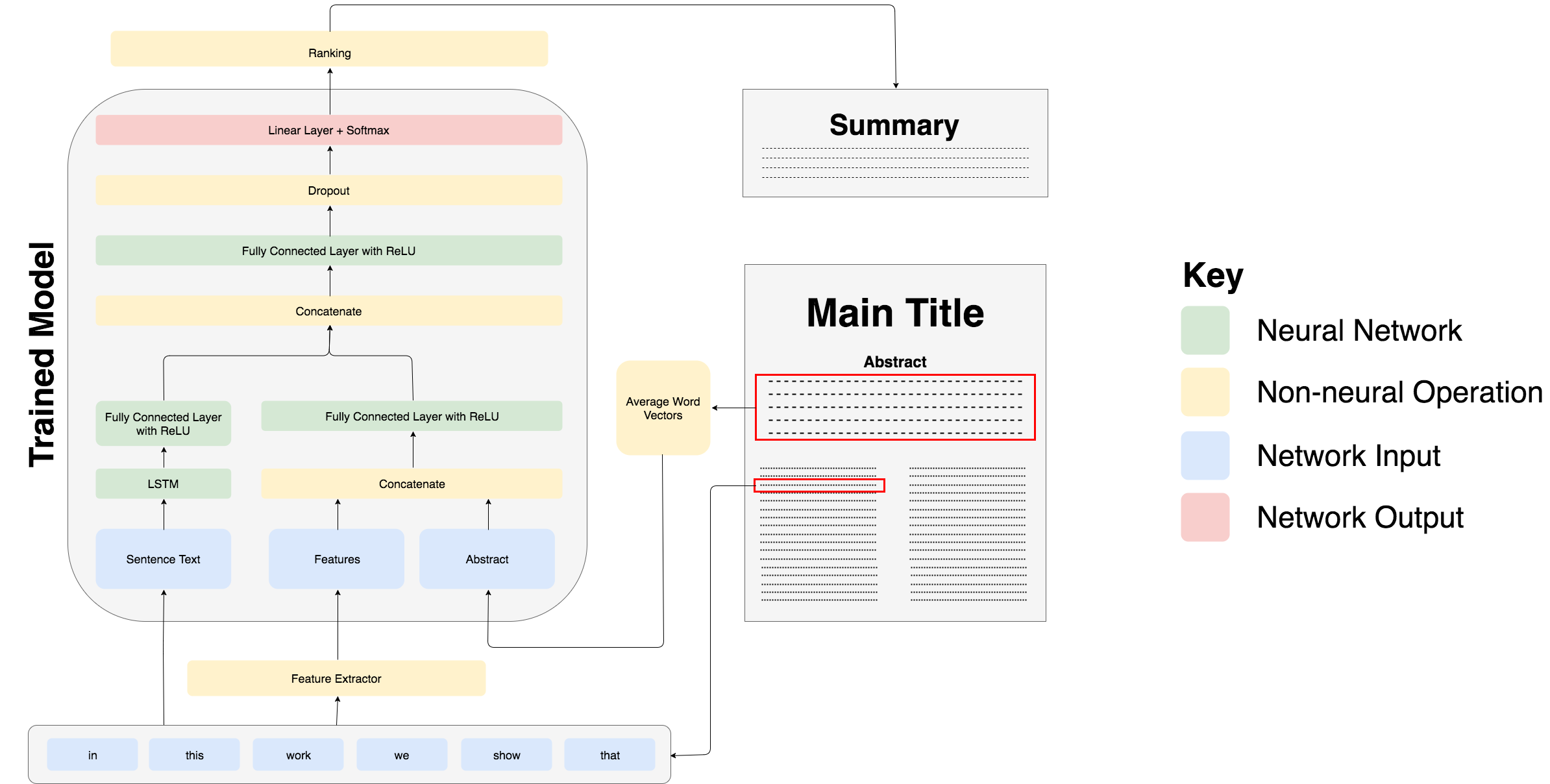
When doing any kind of research, one of the most arduous tasks is to read through hundreds of papers to do a literature review. This work aims to produce a method of reducing the time required for this task, by developing algorithms to automatically summarise scientific papers. These produce short summaries which supplement the abstract of a paper, so that if readers require a deeper understanding of a paper than its abstract can provide, they do not have to trawl through its main, dense text. This work uses the approach of extractive summarisation, which finds sentences from within the paper itself that best summarise it.
In the past, extractive summarisation has been a feature engineering task. However, recent research has focused on neural approaches to summarisation, which can be very data-hungry but produce far better results. However, few large datasets exist for this task and none for the domain of scientific publications.
In this work, we introduce a new dataset for summarisation of computer science publications by exploiting a large resource of author provided summaries and show straightforward ways of extending it further. We develop models on the dataset making use of both neural sentence encoding and traditionally used summarisation features. We then show that models which encode sentences with deep neural networks and combine this encoding with a small feature set for each sentence perform best, significantly outperforming well-established baseline methods.
References
- A Supervised Approach to Extractive Summarisation of Scientific Papers. Ed Collins, Isabelle Augenstein, Sebastian Riedel. To appear in Proceedings of CoNLL, July 2017, [pdf].
- A Supervised Approach to Extractive Summarisation of Scientific Papers. Ed Collins. UCL MEng thesis, May 2017, [pdf].
Learning Python Code Suggestion with a Sparse Pointer Network
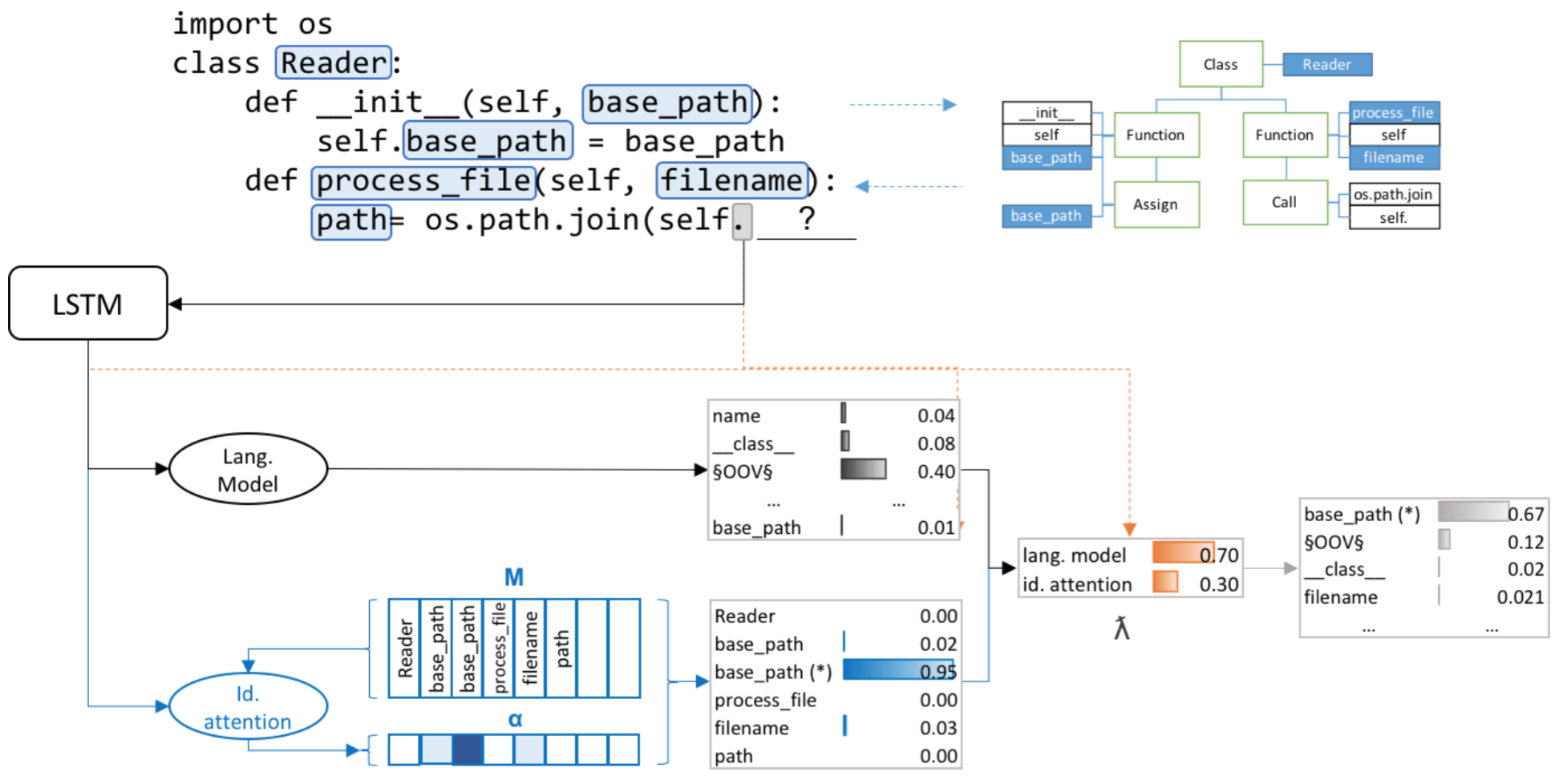
To enhance developer productivity, all modern integrated development environments (IDEs) include code suggestion functionality that proposes likely next tokens at the cursor. While current IDEs work well for statically-typed languages, their reliance on type annotations means that they do not provide the same level of support for dynamic programming languages as for statically-typed languages. Moreover, suggestion engines in modern IDEs do not propose expressions or multi-statement idiomatic code. Recent work has shown that language models can improve code suggestion systems by learning from software repositories. This paper introduces a neural language model with a sparse pointer network aimed at capturing very long-range dependencies. We release a large-scale code suggestion corpus of 41M lines of Python code crawled from GitHub. On this corpus, we found standard neural language models to perform well at suggesting local phenomena, but struggle to refer to identifiers that are introduced many tokens in the past. By augmenting a neural language model with a pointer network specialized in referring to predefined classes of identifiers, we obtain a much lower perplexity and a 5 percentage points increase in accuracy for code suggestion compared to an LSTM baseline. In fact, this increase in code suggestion accuracy is due to a 13 times more accurate prediction of identifiers. Furthermore, a qualitative analysis shows this model indeed captures interesting long-range dependencies, like referring to a class member defined over 60 tokens in the past.
References
- Deep Learning with Neural Attention for Code Suggestion. Avishkar Bhoopchand. UCL MSc Dissertation 2016 [pdf]
- Learning Python Code Suggestion with a Sparse Pointer Network. Avishkar Bhoopchand, Tim Rocktäschel, Earl Barr and Sebastian Riedel. arXiv [pdf]
Back-to-the-Future Networks: Referring to the Past to Predict the Future
Current language modeling architectures often use recurrent neural networks. Recently, various methods for incorporating differentiable memory into these architectures have been proposed. When predicting the next token, these models query information from a memory of the recent history and thus can facilitate learning mid- and long-range dependencies. However, conventional attention models produce a single output vector per time step that is used for predicting the next token as well as the key and value of a differentiable memory of the history of tokens. In this project, we propose a key-value attention mechanism that produces separate representations for the key and value of a memory, and for a representation that encodes the next-word distribution. The architecture of this model is presented below:
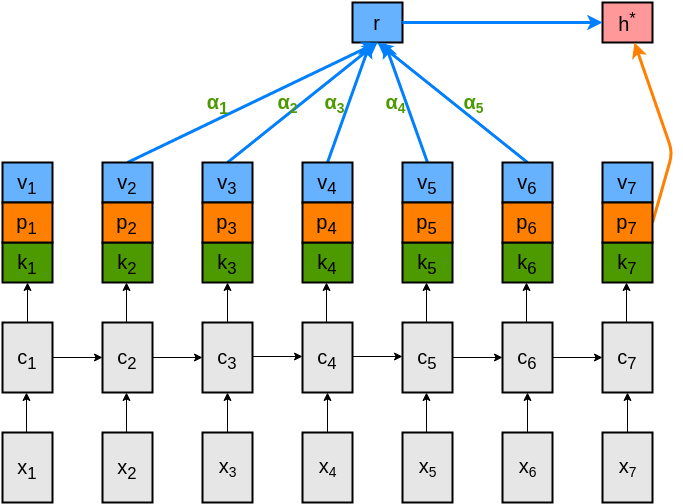
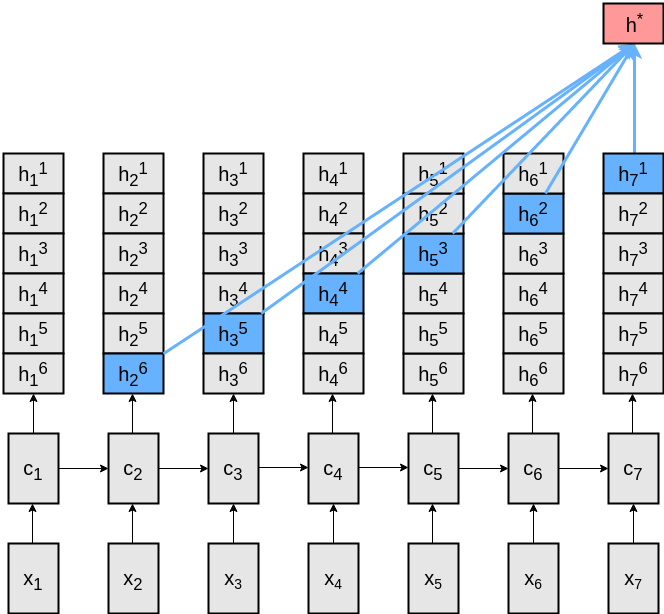
This usage of past memories outperforms existing memory-augmented neural language models on two corpora. Yet, we found that it mainly utilizes past memory only of the previous five representations. This led to the unexpected main finding that a much simpler model which simply uses a concatenation of output representations from the previous three-time steps is on par with more sophisticated memory-augmented neural language models.
References
- Back-to-the-Future Networks: Referring to the Past to Predict the Future. Michal Daniluk. UCL MSc Dissertation 2016 [pdf]
- Frustratingly Short Attention Spans in Neural Language Modeling. Michal Daniluk, Tim Rocktäschel, Johannes Welbl and Sebastian Riedel. ICLR 2017 [pdf]
- Frustratingly Short Attention Spans (ICLR 2017) - A Summary. Blog Entry by TTIC student [HTML]
Exploiting Linguistic Task Hierarchies for Sequence Tagging in Natural Language Processing
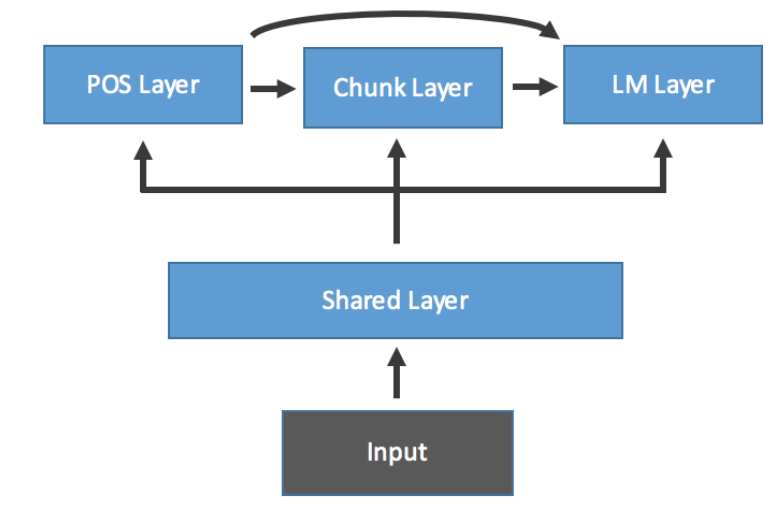
This thesis investigates whether hierarchical structure in linguistic tasks can be used to improve the performance of Natural Language Processing algorithms. In particular, we investigate one such hierarchy (Part of Speech Tagging, Chunk Tagging and Language Modeling) in the context of a Neural Network algorithm, and find that adaptations to the algorithm that exploit the hierarchy improve performance.
Furthermore, we show that by training the unsupervised (Language Modeling) and supervised (Part of Speech Tagging and Chunk Tagging) tasks alternately we can conduct semi-supervised learning, and so improve performance for Part of Speech Tagging and Chunk Tagging.
References
- Exploiting Linguistic Task Hierarchies for Sequence Tagging in Natural Language Processing. Jonathan Godwin. UCL MSc Dissertation 2016 [pdf]
- Deep Semi-Supervised Learning with Linguistically Motivated Sequence Labeling Task Hierarchies. Jonathan Godwin, Pontus Stenetorp and Sebastian Riedel. arXiv 2016 [pdf]
Learning to Reason With Adaptive Computation
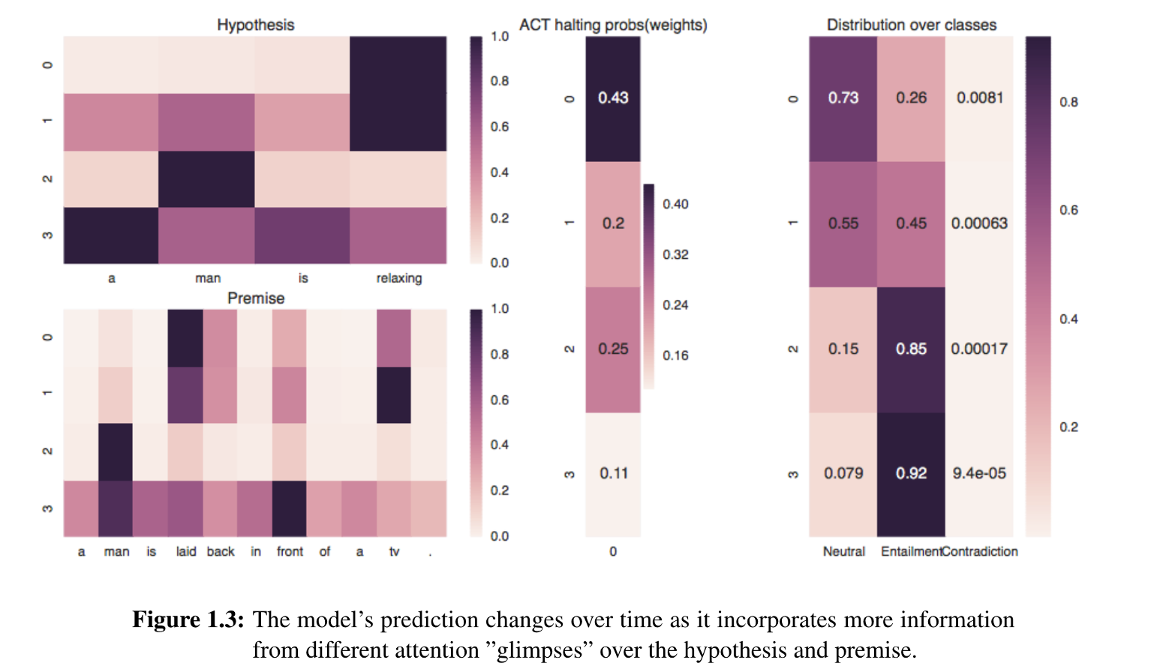
When humans resolve entailment problems, we are adept at not only breaking down a large problem into sub-problems, but also re-combining the sub-problems in a structured way. Often in simple problems, only the first step is necessary. However, in more complicated cases, it can be necessary to both decompose and then reason.
This thesis investigates whether we can devise a method for combining inferences over a multi-sentence problem which adapts it’s time complexity to the difficulty of the problem in an organic way. Can such a method provide insight into how inferences are resolved? Finally, can such a method be naturally more efficient by moderating it’s computation without suffering with respect to task performance?
We demonstrate the effectiveness of adaptive computation for varying the inference required for examples of different complexity and show the dual application of models designed for Machine Reading applied to textual entailment. We introduce the first model involving Adaptive Computation Time which provides a performance benefit on top of a similar model without an adaptive component.
References
- Learning to Reason with Adaptive Computation. Mark Neumann. UCL MSc Dissertation 2016 [pdf]
- Learning to Reason With Adaptive Computation. Mark Neumann, Pontus Stenetorp, and Sebastian Riedel. Interpretable Machine Learning for Complex Systems at the 2016 Conference on Neural Information Processing Systems (NIPS) [pdf]
Semantic parsing from English to AMR using Imitation Learning
The Abstract Meaning Representation (AMR) is a recent standard for representing the semantics of English text that is not domain-specific and provides a machine- interpretable format that encapsulates key parts of the meaning of a sentence. An automated parser to convert English sentences to AMR would be very helpful in machine translation, human-computer interaction and other areasasd
We develop a novel transition-based parsing algorithm to obtain results in this English to AMR translation task that are close to state-of-the-art using simple imitation learning, in which the parser learns a statistical model by imitating the actions of an expert on the training data.
We attempt to improve upon this with more sophisticated imitation learning algorithms that permit the learned parser to ask for advice from the expert in situations that the expert by itself would not visit. This approach creates new sequences of actions that extend the training data into regions of search space that better represent the states that the learned parser is likely to visit in practice, and hence should improve performance. We take two existing algorithms for comparison (V-DAgger and LOLS), and find that taking elements of each leads to a hybrid algorithm (DI- DLO) with higher performance than either of the existing algorithms on the AMR parsing problem.
References
- Semantic parsing from English to AMR using Imitation Learning, James Goodman, UCL MSc Dissertation [pdf].
- Noise reduction and targeted exploration in imitation learning for Abstract Meaning Representation parsing, James Goodman, Andreas Vlachos and Jason Naradowsky, Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics [pdf].